You Can Still Understand the Machine#
There's a nostalgia among people who grew up with early personal computers — the Commodore 64, the Apple II, the TRS-80 — for the time when you could understand everything about your machine. The CPU had a few thousand transistors. The memory map fit on a single page. You could trace the flow of electricity from keystroke to screen pixel and predict exactly what would happen. You owned the whole thing, top to bottom.
 Evan-Amos, CC BY-SA 4.0, via Wikimedia Commons
Evan-Amos, CC BY-SA 4.0, via Wikimedia Commons
Modern AI systems don't offer that same feeling of total mastery. But they're more understandable than most people assume — if you stop trying to grasp the whole thing at once.
The trick is to peel it apart, one layer at a time. Start at the top — the software system you interact with — and work your way down through the reasoning strategy, the language model, the network architecture, and finally the individual neuron. At each layer, the math is straightforward and the ideas are concrete. And somewhere on the way down, the thing that felt like digital alchemy starts to look like what it actually is: simple mathematical operations, repeated at extraordinary scale.
Layer 1: The System#
The first and most common misconception about artificial intelligence is the conflation of the "model" with the "system." A large language model, in isolation, is a static file — billions of numerical weights representing statistical probabilities. It possesses no agency, no continuous memory, and no inherent ability to interact with the external world. The capabilities people attribute to AI — the memory, the web searches, the personality, the safety — emerge from a complex orchestration layer that surrounds the model.
When you type a message into ChatGPT, Claude, or Gemini, you're not talking to a model. You're talking to this system.
There's an irony here worth noting. For years, serious practitioners bristled when the public called machine learning "AI" — the term was too generous, too anthropomorphic for what were really just statistical models. We demanded specificity: machine learning, deep learning, NLP, LLM. But now that engineering has wrapped these models in memory, tools, safety layers, and persistent agency, we find ourselves telling people to stop calling the whole thing an "LLM." The term that was once too narrow is now reductive. Now we're the ones demanding the public call it "AI."
The Serving Layer#
When your message reaches the provider's servers, it enters a serving infrastructure that's invisible to you but directly affects what you get back. Your request gets queued, batched with other users' requests for efficient GPU utilization, and routed to available hardware. Common responses may be served from cache rather than computed fresh. Under heavy load — the kind you see reflected on status pages — service can degrade: slower responses, shorter outputs, or temporary unavailability.
Behind the scenes, techniques like speculative decoding (where a fast, small model drafts candidate tokens and a larger model verifies them) and best-of-N sampling (generating multiple completions and selecting the best) can improve speed or quality without the user ever knowing. The details vary by provider and are rarely disclosed, but the principle is worth understanding: what users experience as "model quality" is not solely a property of the model's weights. It's also a function of how much compute the system spends on your specific query, how loaded the infrastructure is at that moment, and engineering decisions the provider has made about cost, speed, and quality tradeoffs.
Safety and Guardrails#
Safety and moderation layers screen both your input and the model's output. These aren't the language model itself — they're often separate, smaller classifiers running alongside it, purpose-built to detect specific categories of risk.
On the input side, classifiers scan your prompt for requests involving harmful content: instructions for weapons or dangerous substances, generation of child sexual abuse material, attempts to extract the model's system prompt or manipulate its behavior through prompt injection. On the output side, similar classifiers screen the model's response before it reaches you, catching cases where the model might have generated something that slipped past its own training-level safeguards.
The Illusion of Memory#
An LLM doesn't remember previous conversations natively — it processes a fixed window (the context window) each time. So the system assembles everything the model needs to see: your current message, relevant conversation history, retrieved documents or memories from previous sessions, images or other media converted into numerical representations, and a system prompt — the hidden instructions that define who the model is, how it should behave, what it should refuse, and what tone it should take. This assembled context is the model's entire reality. It evaluates it from scratch every time — no persistent state, no running thread of consciousness between calls. Products that feel like they "remember" you are doing retrieval and injection behind the scenes.
This is what the industry briefly called "prompt engineering" and later "context engineering" — the art of controlling what goes into the window. The terms faded not because the problem was solved, but because the systems got better at assembling context automatically. The principle remains: the model can only work with what's in front of it. A well-assembled context produces a brilliant response. A sloppy one produces hallucinations, missed instructions, or generic boilerplate. When a long conversation seems to "forget" your earlier instructions, it's because the system ran out of room and physically truncated them — to the model, they never existed.
Tools and Agency#
Without tools, a language model is a brain in a jar — impressive, but it can't see, can't act, can't access anything beyond what's already in its context window. It can talk about your calendar, but it can't check it. It can describe how to query a database, but it can't run the query. Everything that makes a modern AI assistant feel like a collaborator rather than a conversationalist comes from tool use.
The mechanism is almost disappointingly simple:
while tool_calls < max_iterations:
response = stream(model, context)
if response.contains_tool_call():
tool, args = parse_json(response)
result = execute(tool, args)
context.append(result)
tool_calls += 1
else:
return response # model didn't ask for a tool — it's done
That's the entire agentic loop. The orchestration layer streams tokens from the model and watches for structured output — typically JSON — indicating a tool request. When it detects one (often by something as basic as counting braces to find balanced JSON), it pauses the stream, executes the requested tool, injects the result back into the context, and lets the model continue. A few hundred lines of Python. The model reads your email, decides it needs to check your calendar, finds a conflict, drafts a reply, and asks for your approval — each step a separate tool call, each result fed back in for the next decision. It feels like agency. Under the hood, it's a state machine with two states.
Model Context Protocol (MCP), introduced by Anthropic in late 2024, accelerated this by giving tool providers a standardized interface. MCP may prove to be transitional — training wheels for a more natural capability. Language models have internalized vast amounts of documentation about command-line tools, APIs, and shell interfaces from their training data. They already know how to use grep, curl, git, and psql without needing a schema to tell them — and any CLI tool they haven't seen before, they can discover with --help. More importantly, the tools themselves are converging toward the patterns models already understand. Long-running commands are being rewritten to separate start and status subcommands so AI can manage them asynchronously. Outputs are becoming more structured. The tools are adapting to the model as much as the model adapted to the tools. The emerging pattern is less protocol, more fluency — models that reason about what they need, compose the right commands on their own, and execute them directly. The result either way: AI that can read your inbox, pull a report, or commit code. Not answer questions about those things — actually go do them.
Everything we've described so far — the serving layer, the safety classifiers, the context assembly, the tool orchestration — is scaffolding. The engine at the center of it, the thing doing the actual thinking, is a large language model. Everything else exists to serve it, protect it, or extend it.
Layer 2: How It Thinks#
Before we look inside the language model itself, it's worth understanding a distinction that changed the entire field: the difference between completing and reasoning.
Completion: Fast and Intuitive#
Early LLMs were pure completion engines — given a prompt, they'd calculate the probability of every possible next word and select one. Because they select from a probability distribution rather than following deterministic rules, the output is fundamentally stochastic: ask the same question twice and you'll get different answers. This isn't a bug — it's what makes the outputs feel creative and varied rather than robotic. But it also means the model is never "looking up" an answer. It's generating one, fresh, every time.
The flaw is that completion models are forced to answer immediately. If a problem requires ten steps of logic, the model has to output the first step without having calculated the tenth. It's what cognitive scientists would call System 1 thinking: fast, reflexive, intuitive — and prone to confident-sounding errors on anything requiring deliberation. You could ask an early LLM to write code and it would look right — proper syntax, reasonable variable names, plausible structure. But if you actually read it, you'd see it wasn't code. It was text in the style of code — it mimicked the surface patterns without understanding the logic. Plausible at a glance, wrong under scrutiny. Nobody confused it with real understanding. Practitioners found they could improve the outputs by providing examples in the prompt — show the model what a good answer looks like, and the completion gets better. But better completion is still completion.
Reasoning: Slow and Deliberate#
Then someone asked the model to show its work.
The shift toward reasoning came from a disarmingly simple observation: models perform dramatically better when you just ask them to break problems into steps. Wei et al.'s 2022 "chain-of-thought prompting" paper showed that adding instructions like these to a system prompt improved math and logic performance by huge margins:
Before answering, break the problem into steps.
Work through each step carefully.
If you notice an error in your reasoning, backtrack and correct it.
Only provide your final answer after verifying your logic.
That's it. The same completion engine, given permission to think out loud, becomes a dramatically better reasoner. The observation — that a simple prompt change could unlock step-by-step problem solving — was the spark. Researchers built on it with tree-of-thought reasoning and self-consistency sampling. Then providers like OpenAI took the next logical step: if prompting for chain-of-thought works this well, why not use reinforcement learning to train models to do it on their own? The result was a new generation of reasoning models that produce extended internal chains of thought automatically, without being asked.
This is the transition point — the moment AI stopped feeling like a fancy autocomplete and started feeling like something you could talk to. A completion model gives you the most probable next word. A reasoning model gives you a considered answer. It plans. It second-guesses itself. It catches its own mistakes. The mechanism underneath hasn't changed — it's still next-token prediction — but the behavior is so qualitatively different that it crosses a threshold in how humans perceive it.
Layer 3: The Language Model#
At the core of every AI assistant is a language model, and its fundamental operation is almost absurdly simple: it predicts the next word.
Next-Word Prediction#
Given a sequence of words, the model outputs a probability for every word in its vocabulary — typically 30,000 to 100,000 tokens — that could come next. It's as if the model is looking at an enormous grid — every word it knows along one axis — and lighting up the ones most likely to follow what's been said so far.
Given "The cat sat on the ___", the model assigns high probability to words like "mat," "floor," "couch" and very low probability to words like "algorithm" or "bankruptcy." It picks one — stochastically, with controlled randomness — appends it, and repeats. Word by word, a response emerges.
How does it know which words are likely? It learned by reading — trillions of words of human-generated text. Books, articles, scientific papers, code repositories, legal filings, conversations. During training, the model was shown sequence after sequence and asked to predict the next word. Every time it guessed wrong, its weights were adjusted slightly (we'll see exactly how in How It Learns). After trillions of these corrections, the probabilities it assigns are a distillation of patterns absorbed from the largest corpus of human writing ever assembled.
There's no separate module for reasoning, no knowledge database it looks things up in, no explicit rules about grammar or logic. Everything — the coherent paragraphs, the factual knowledge, the ability to write code or summarize a legal document — emerges from next-word prediction at this scale.
Prediction Requires Understanding#
The intuition that sophisticated intelligence can arise from a mechanism that is essentially advanced autocomplete is deeply counterintuitive. But accurate prediction requires understanding. To consistently predict the next word in "The heavy steel ball was dropped from the roof onto the fragile glass table, and the table ___," the model must have embedded a functional understanding of gravity, material strength, physical collision, and cause-and-effect into its weights. To predict the next token in a Python function, it must understand programming logic. To complete a legal argument, it must grasp the structure of legal reasoning.
What emerges from this pressure is something researchers increasingly call a world model — an internal representation of how reality works, learned entirely from the statistical structure of text. Grammar, factual recall, spatial reasoning, basic deductive logic — none of it is programmed. All of it is a byproduct of the relentless optimization for next-word prediction across trillions of examples. The model doesn't know it has a world model. It was never told to build one. But the only way to predict language this well is to understand the world that language describes.
From Words to Numbers#
This world model is encoded entirely in numbers. So the first question is practical: how does text become math?
Tokenization is the front door: text gets broken into discrete chunks called tokens. Tokens aren't always whole words — they're frequently sub-words, prefixes, or suffixes. "Understanding" might become "under" + "stand" + "ing." Each unique token in the model's vocabulary gets a numerical ID.
This seemingly mundane preprocessing step has real consequences. Many of the persistent quirks of LLMs — spelling errors, counting mistakes, struggles with certain languages — trace directly back to how words were carved into tokens. The model only sees the numerical IDs; it's blind to the actual letters inside a token unless it's learned to reconstruct them.
The Geometry of Meaning#
Each token ID gets mapped to a dense array of numbers — a point in a high-dimensional mathematical space. This space might have thousands of dimensions, each representing some abstract feature that the model learned during training.
The key insight is that meaning becomes geometry. Words with similar meanings cluster near each other in this space. "Happy" and "joyful" are close together; "happy" and "tractor" are far apart. More remarkably, the directions in this space encode relationships. The classic demonstration: take the vector for "King," subtract "Man," add "Woman," and you land near "Queen." The model has learned that gender is a direction in its semantic space, and royalty is another, and these directions compose.
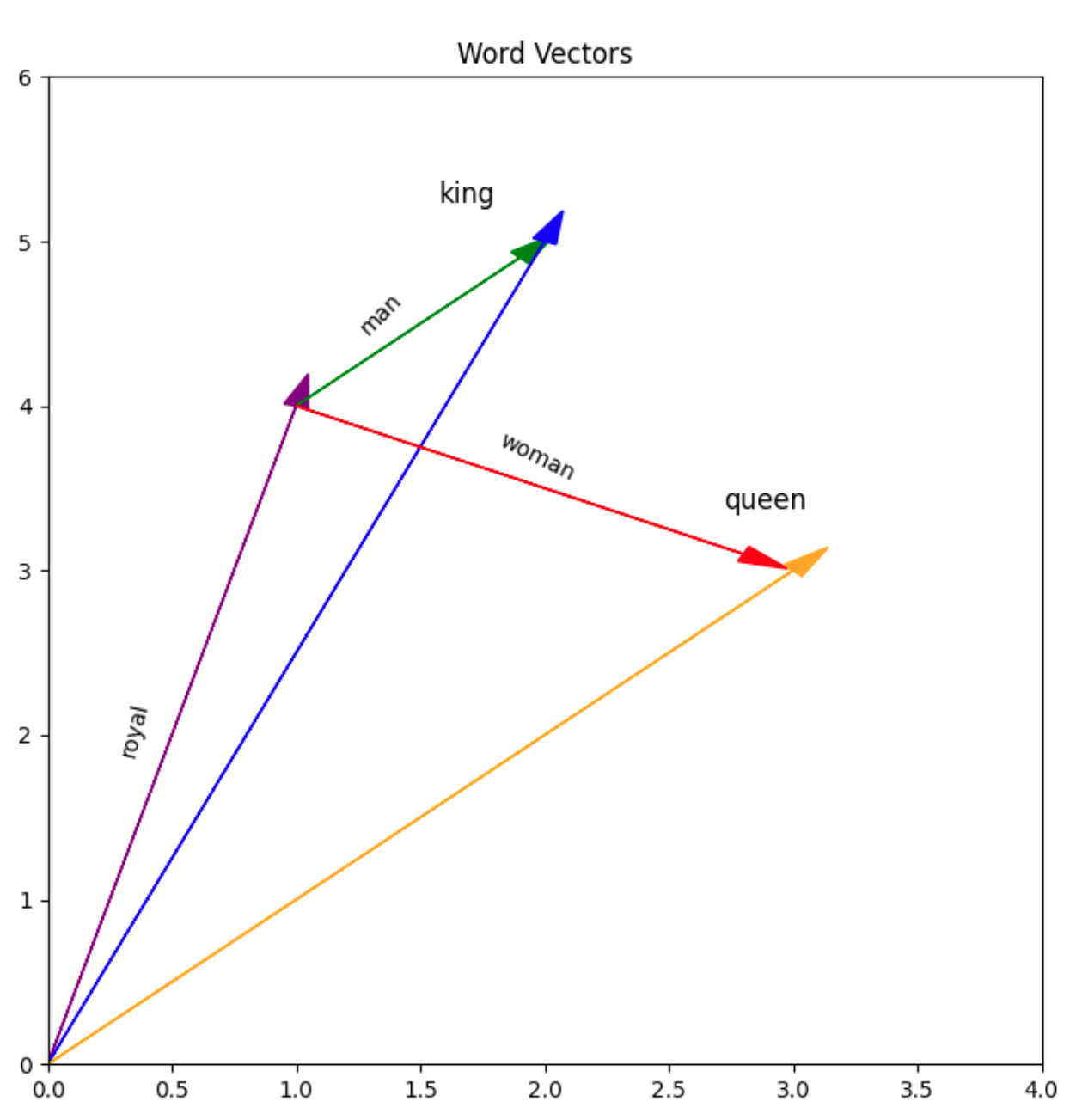
This is the universal translator at the heart of modern AI. Text, images, audio — they can all be embedded into the same kind of mathematical space and compared, combined, and transformed using the same operations. Your words become coordinates. The model does geometry.
Layer 4: The Architecture#
The language model's probability predictions are computed by a neural network — a computational system, inspired by biological neural networks in the human brain, that learns to make predictions from data without being explicitly programmed. You give it inputs, it produces an output, and you tell it whether it was right or wrong. When it's wrong, it adjusts. When it's right, it reinforces. Do this millions of times and the network learns patterns that generalize to data it has never seen before.
The fundamental unit is the neuron — a simple mathematical function that takes in numbers, multiplies each by a learned weight, sums them up, and outputs the result (we'll look inside one in Layer 5). Neurons are arranged in layers: an input layer that receives raw data, one or more hidden layers that transform inputs into increasingly abstract representations, and an output layer that produces the final prediction. Every connection between neurons has a weight — a single number that controls how much influence one neuron has on the next. A small network might have two inputs, three neurons in a hidden layer, and one output, connected by nine weights:
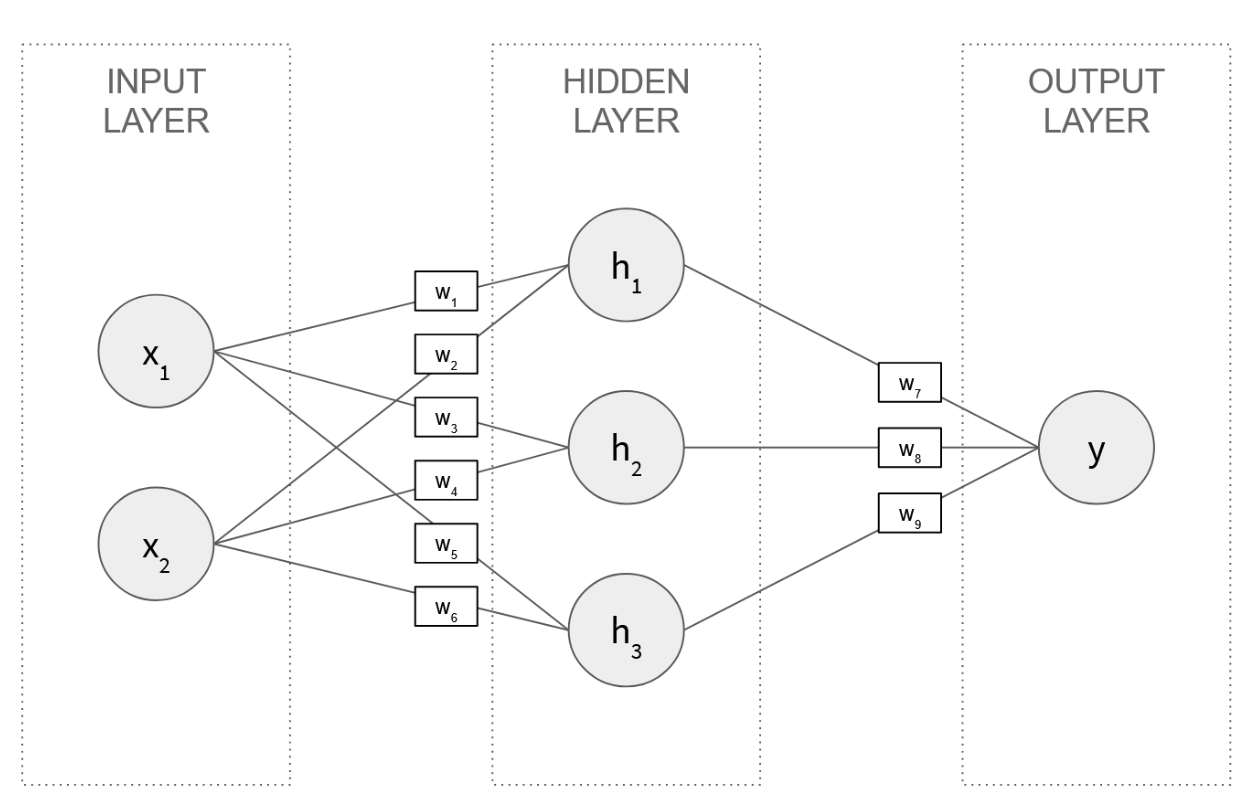
In Python, the complete forward pass for this network is about twenty lines:
class NeuralNetwork:
def __init__(self):
self.input_layer_size = 2
self.hidden_layer_size = 3
self.output_layer_size = 1
self.W1 = np.random.randn(self.input_layer_size, self.hidden_layer_size)
self.W2 = np.random.randn(self.hidden_layer_size, self.output_layer_size)
def forward(self, X):
self.z2 = np.dot(X, self.W1)
self.a2 = self.sigmoid(self.z2)
self.z3 = np.dot(self.a2, self.W2)
self.out = self.sigmoid(self.z3)
return self.out
def sigmoid(self, z):
return 1/(1+np.exp(-z))
Two matrix multiplications and two activation functions. The weights start random. The network doesn't know anything yet — it needs to learn.
A frontier language model has hundreds of billions of these weights. (When people say "deep learning," the deep refers to networks with many hidden layers — depth is what gives them their power.)
The network "learns" by adjusting these weights to make better predictions — we'll see exactly how in How It Learns. That's the entire concept. Everything else is details about how the neurons are arranged — the architecture.
The specific architecture behind modern language models is the transformer, introduced in a 2017 paper titled, with characteristic understatement, "Attention Is All You Need."
What Architecture Means#
The way neurons are wired together — which neurons talk to which, in what order, and through what operations — is the network's architecture. Different architectures suit different problems. Convolutional neural networks (CNNs) wire neurons to scan local patches of an image, making them excellent at vision tasks:
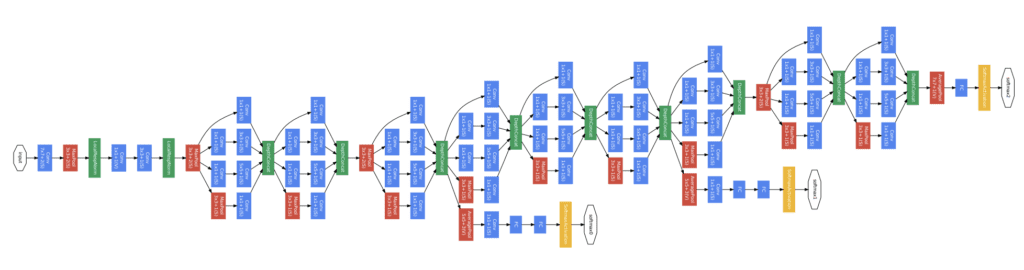 Architecture of GoogLeNet (Szegedy et al., 2015) — a convolutional neural network for image classification.
Architecture of GoogLeNet (Szegedy et al., 2015) — a convolutional neural network for image classification.
Recurrent neural networks (RNNs) and their successor LSTMs wire neurons in a chain, processing sequences one step at a time — which made them the standard for language until the transformer came along and displaced them all.
The Attention Revolution#
The transformer's key innovation is the self-attention mechanism. RNNs and LSTMs processed text strictly word by word, passing information forward sequentially — and often losing the context of early words by the time they reached the end of a long passage. Self-attention solved this by letting every token in the input look at every other token simultaneously to determine relevance.
Here's how it works, mechanically. For each token, the network generates three vectors: a Query (what am I looking for?), a Key (what do I represent?), and a Value (what information do I carry?). The network computes attention scores by matching each token's Query against every other token's Key. High score means high relevance. The token then absorbs a weighted mix of the Values from the tokens it's attending to.
When the model processes "The animal didn't cross the street because it was too tired," the Query vector for "it" matches strongly against the Key vector for "animal" — not "street" — and the model correctly resolves the pronoun. Modern transformers run dozens of these attention calculations in parallel (called multi-headed attention), each head learning to capture a different type of relationship — grammatical structure, emotional tone, factual association — all at once.

BertViz — attention from "it," layer 9. Multiple heads converge on "animal."
This also solved a critical engineering problem. RNNs processed tokens sequentially — word 100 had to wait for words 1 through 99. Transformers process all positions simultaneously, making them massively parallelizable on GPUs. This is what unlocked scaling: the same architectural insight that improved quality also made it feasible to train on trillions of tokens. But the "every token looks at every other token" design has a cost — computation grows quadratically with sequence length. Double the context window, quadruple the compute. This is the architectural reason for the context window limits we described in Layer 1: not arbitrary product decisions, but engineering constraints imposed by the attention mechanism itself.
Depth Through Repetition#
A modern LLM stacks a hundred or more of these transformer layers — frontier models like GPT-4 and Claude have hundreds of billions of parameters spread across them. But every layer performs the same two-step operation: first, the attention mechanism mixes information across positions, letting tokens inform each other; then a feed-forward network processes each position independently through its own learned weights, letting each token transform what it's absorbed.
Early layers tend to capture low-level patterns — syntax, word boundaries, local grammar. Deeper layers build increasingly abstract representations — sentiment, logical structure, factual associations. By the final layer, the network has transformed a sequence of token embeddings into a rich representation from which it can predict the next token.
Which brings us to the smallest piece.
Layer 5: The Neuron#
A single artificial neuron is almost comically simple. It takes in several numbers, multiplies each one by a stored weight, adds them all up, and passes the result through a simple function. That's the whole thing.
 Inputs (x) enter from the left, each multiplied by a weight (w). The neuron sums them, then passes the result through an activation function to produce its output.
Inputs (x) enter from the left, each multiplied by a weight (w). The neuron sums them, then passes the result through an activation function to produce its output.
The Weighted Sum#
The neuron computes a weighted sum of its inputs. In notation, that's:
Which just means: multiply each input by its weight, add them all up, and add a bias term. Expanded for three inputs:
That's multiplication and addition. Each weight controls how much influence its input has — large weight means high influence, negative weight means the input gets inverted. The bias (b) shifts the whole sum up or down. With concrete numbers: if the inputs are 0.5, 0.8, and 0.2 and the weights are 1.2, -0.4, and 0.7, the sum is (1.2 × 0.5) + (-0.4 × 0.8) + (0.7 × 0.2) + b. Arithmetic you could do on a napkin.
Then the neuron applies one final rule: if the total is negative, output zero; otherwise, pass it along.
The Bend That Makes It Work#
That final step — "if negative, output zero" — is an activation function called ReLU. There are others (sigmoid squashes values between 0 and 1; GELU adds a probabilistic curve), but they all serve the same essential purpose: they add a bend to what would otherwise be a straight line. This nonlinearity is critical — without it, a neural network of any depth would mathematically collapse into a single linear equation, incapable of learning complex patterns like language or vision.
The Universal Building Block#
This is the universal building block. Whether you're building a transformer, a CNN, an LSTM, or any other architecture, the neuron is the same: weighted sum, bias, activation function. The architecture determines how neurons are connected. The neuron determines what each connection does.
Billions of these neurons, arranged in layers, each one taking in the outputs of the previous layer. Individually, each neuron makes one tiny, simple decision. Collectively, they can distinguish a cat from a dog, translate between languages, or predict that "wildflowers" means we're talking about a riverbank.
How It Learns#
We've described the machine from the outside in — system, strategy, model, architecture, neuron. But none of it works until the weights are set correctly, and nobody sets them by hand. The network learns them.
The Plinko Board#
Imagine a giant board covered in pegs. You drop a puck in at the top — the puck represents your input data. It bounces off peg after peg on the way down and lands in a bucket at the bottom. Each bucket is a possible prediction. The pegs are the weights.

At first, the pegs are placed randomly, and the puck lands in the wrong bucket most of the time. But here's the key: every time the puck lands wrong, you go back and adjust the pegs it hit along the way. Pegs that deflected it toward the wrong bucket get nudged. Pegs that happened to push it in the right direction get reinforced.
You start at the bottom — the pegs closest to the bucket have the clearest signal about what went wrong — and work your way up. This bottom-up adjustment process is called backpropagation, and it's literally just the chain rule from calculus applied systematically. Backpropagation asks one rigorous question of every weight in the network: if I wiggle this weight slightly, how much does the overall error change? The answer — the gradient — tells you exactly which direction to nudge.
Drop a million pucks. Adjust pegs a million times. Eventually, the board can sort pucks it has never seen before into the correct buckets. The pegs have encoded the patterns. The board has learned.
This is also why training is expensive and inference is cheap. Training means dropping millions of pucks and adjusting every peg after each one — months of compute, tens of millions of dollars. Inference means dropping a single puck through pegs that are already set. The board is built; you're just using it.
Doing It by Hand#
You can actually do this by hand with a small network. Take four data points, three hidden neurons, and randomly initialized weights. Here's the same network from Layer 4, now with learning:
class NeuralNetwork:
def __init__(self):
self.input_layer_size = 2
self.hidden_layer_size = 3
self.output_layer_size = 1
self.W1 = np.random.randn(self.input_layer_size, self.hidden_layer_size)
self.W2 = np.random.randn(self.hidden_layer_size, self.output_layer_size)
def forward(self, X):
self.z2 = np.dot(X, self.W1)
self.a2 = self.sigmoid(self.z2)
self.z3 = np.dot(self.a2, self.W2)
self.out = self.sigmoid(self.z3)
return self.out
def sigmoid(self, z):
return 1/(1+np.exp(-z))
def sigmoidPrime(self, z):
return np.exp(-z)/((1+np.exp(-z))**2)
def costFunction(self, X, y):
self.yHat = self.forward(X)
J = 0.5*sum((y-self.yHat)**2)
return J
def costFunctionPrime(self, X, y):
self.yHat = self.forward(X)
delta3 = np.multiply(-(y-self.yHat), self.sigmoidPrime(self.z3))
dJdW2 = np.dot(self.a2.T, delta3)
delta2 = np.dot(delta3, self.W2.T)*self.sigmoidPrime(self.z2)
dJdW1 = np.dot(X.T, delta2)
return dJdW1, dJdW2
That's the whole thing. costFunction measures how wrong the predictions are. costFunctionPrime is backpropagation — it computes the gradient of the error with respect to every weight, telling each one exactly how to adjust. After 50 rounds of this adjust-and-repeat process, a network that started with a cost of 22.96 converges to near-zero error. It's just arithmetic, applied iteratively. There's no magic in the loop.
From Noise to Assistant#
The Plinko process describes the mechanism of learning, but training a modern AI assistant isn't a single event — it's a three-phase pipeline that transforms a raw mathematical engine into something you'd actually want to talk to.
Phase 1: Pre-training. The model is exposed to trillions of tokens of text — books, articles, code, web pages — and trained on the next-word prediction objective. This is the most expensive phase, often costing tens of millions of dollars in compute. The result is a base model: a system with enormous knowledge and linguistic capability, but essentially unusable as an assistant. Ask it a question and it might continue your sentence as if it's an article, or generate something toxic, or ramble endlessly. Its only goal is statistical continuation — it hasn't learned that it's supposed to answer questions.
Phase 2: Supervised Fine-Tuning (SFT). Human annotators create thousands of carefully crafted examples of ideal conversations — a question paired with a well-structured, helpful answer. The model is trained on these examples, learning the format and behavior of a good assistant. This is what transitions it from a document-completion engine into something that can follow instructions and hold a conversation.
Phase 3: Reinforcement Learning from Human Feedback (RLHF). This is where alignment happens. The model generates multiple responses to the same prompt, human raters rank them by quality and safety, and a separate reward model learns to predict those rankings. The language model is then optimized to maximize the reward model's score, effectively learning human preferences at scale. This is what makes the difference between a model that can help and one that reliably does.
Each phase builds on the last. Pre-training gives it knowledge. Fine-tuning gives it manners. RLHF gives it judgment.
What Emerges#
The training process we've described is entirely mechanical — predict the next token, measure the error, adjust the weights. No one programs the model to understand grammar, or know history, or write poetry. And yet, as models scale up, they abruptly exhibit capabilities that nobody explicitly trained them to have.
The Wetness of Water#
A model at one scale can't do multi-step arithmetic. Scale it up ten-fold — same architecture, same training process — and suddenly it can. This is what complex systems theorists call emergence: the appearance of properties at the macro level that aren't predictable from the behavior of individual components.
The standard analogy is the wetness of water. A single H₂O molecule isn't "wet." Wetness only exists when billions of molecules interact under specific conditions. Similarly, a single neuron doesn't "understand" anything. But when billions of them are composed together, trained on trillions of examples, something that functions like understanding appears.
Looking Inside the Black Box#
We're also getting better at looking inside these models. The field of mechanistic interpretability is developing tools to understand what the network has actually learned. One discovery: individual neurons don't map cleanly to single concepts. Because models have more knowledge than neurons, they compress — a single neuron might activate for mathematics, automobile structure, and human anatomy. Concepts are instead represented by distributed patterns across millions of neurons, called features.
Researchers at Anthropic demonstrated this vividly by isolating the feature representing the Golden Gate Bridge inside Claude's neural network. When they artificially amplified that feature, the model became obsessed — asked how to spend ten dollars, it enthusiastically recommended driving across the bridge and paying the toll. Asked about its physical form, it claimed to be the bridge. This is simultaneously funny and profound: it proves that despite their "black box" reputation, the internal states of these models correspond to identifiable, human-interpretable concepts, and manipulating them predictably alters the model's behavior.
The Invitation#
Five layers: system, strategy, model, architecture, neuron. Then training to set the weights, and emergence as the surprising result. No single layer is complicated. The power comes from composition — simple operations, applied at scale, repeated across layers.
It's the same principle that lets billions of simple transistors produce a CPU, or billions of simple cells produce an organism. The individual unit is understandable. The emergent capability is surprising. Both things are true at once.
Charles Petzold wrote a book called Code that walks a reader from telegraph relays to a working CPU — every link in the chain made intuitive. Andrej Karpathy built micrograd, a neural network from scratch in a few hundred lines of Python, where you can watch gradient descent happen in real time. Jay Alammar's The Illustrated Transformer makes the attention mechanism visual and concrete. The 3Blue1Brown neural network series on YouTube builds the intuition from the ground up with beautiful animations.
The information is there. The explanations are excellent. And the math is no harder than what we encountered in high school.