LIT Platform#
Vibe data science: the AI executes — building datasets, designing architectures, running experiments, debugging failures — while you provide the domain expertise, judgment, and direction that only comes from experience. Your only interface is chat.
LIT Platform is built for this workflow. It runs locally, everything stays on your machine, and it gives an AI collaborator exactly the constraints it needs to navigate a real data science problem without floundering.
See what this looks like in practice →
Chat & Agents#
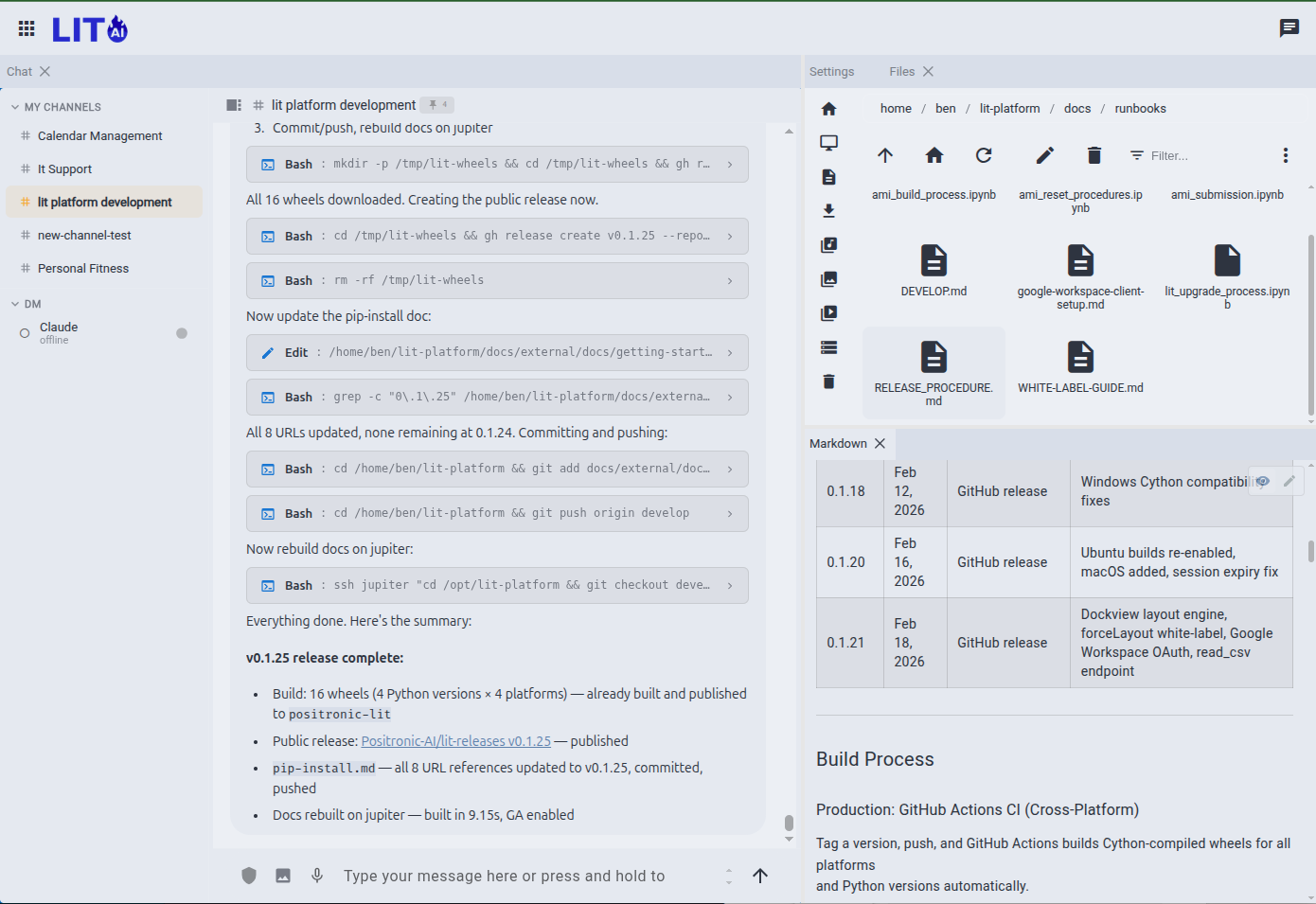
This is where the collaboration happens. You talk; the agent reads your data, runs experiments, writes pipelines, and reports back. Tool calls stream inline as they happen — you see the full inner monologue, not a summary.
Chat Interface#
A persistent session where the AI has access to your full toolkit — file system, CLI, MCP servers, external APIs. Ask a quick question or kick off a multi-hour autonomous run from the same interface.
Autonomous Agents#
The heartbeat feature: your agent wakes up on a configurable interval, runs its assigned work, and posts results to a channel. Monitor a data pipeline, summarize overnight training runs, check for new data — without you staying awake to babysit it.
Channels & Direct Messaging#
Persistent, named workspaces for ongoing projects. #model-training accumulates every training update. #data-pipeline captures every monitoring alert. Your conversation history with the agent is always there — searchable, reviewable, resumable.
Multi-Agent Orchestration#
Delegate tasks across a hierarchy of specialized agents. Each agent gets its own system prompt, model selection, and MCP tool configuration. Agents can communicate, delegate subtasks, and report results up the chain.
Deep Learning Studio#
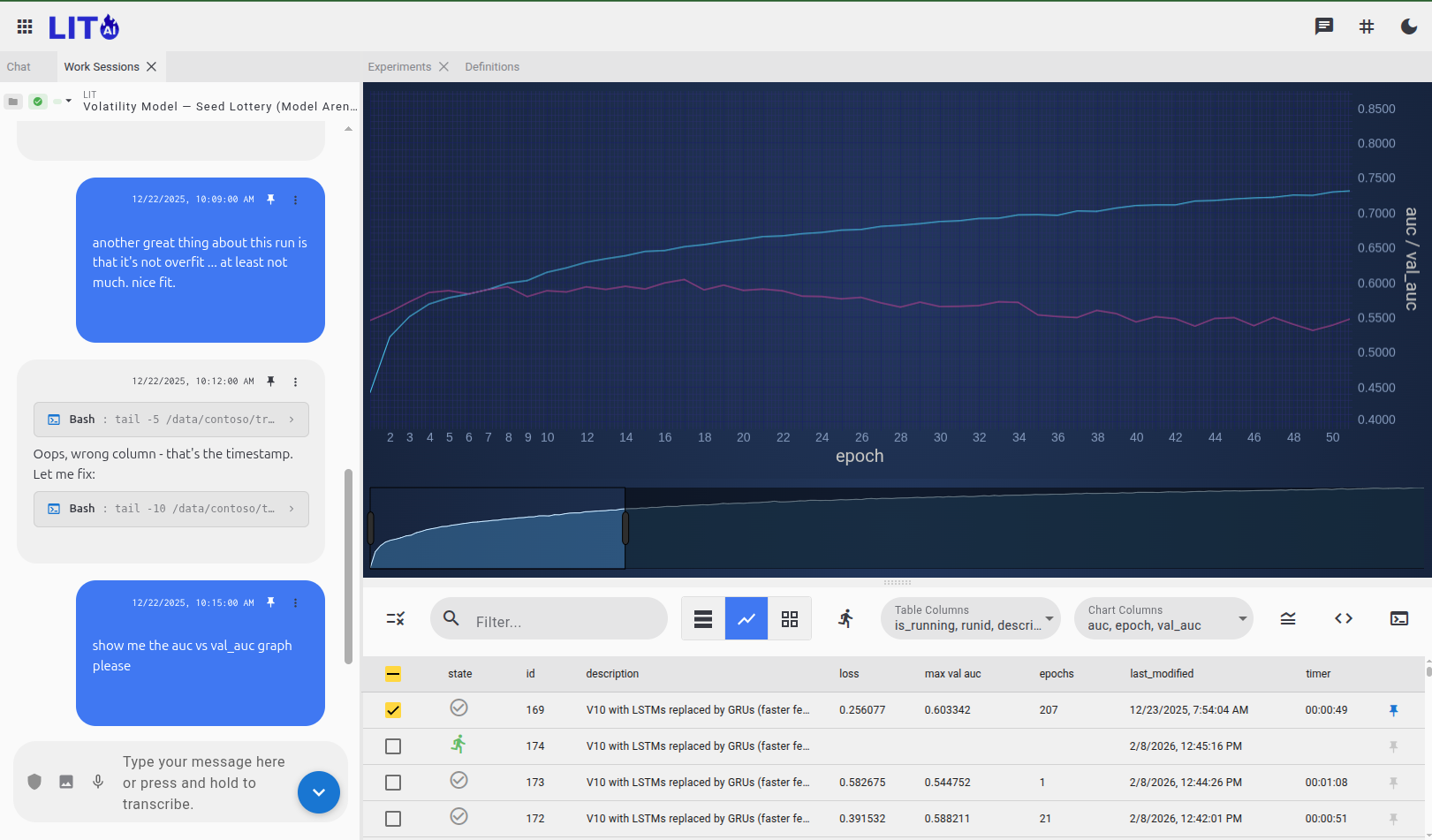
The machinery the AI operates. Build and train custom neural networks — from visual architecture design to production inference. The platform works at three altitudes: reusable components, architectures (how components connect), and experiments (training runs with specific hyperparameters). This structure is what makes AI-driven exploration tractable — the agent can navigate it systematically.
Data Fabric#
Raw data → training-ready datasets. The pipeline handles ingestion, normalization, and lookahead bias prevention. Random access into large-scale datasets processes years of time-series data in milliseconds, making rapid experiment iteration practical.
Pipeline → · Build Automation → · Schemas → · Cache Files → · Data Auditing →
Features#
Reusable feature logic separated from parameterization. Build a library of features that domain experts and data scientists can collaborate on — the AI can discover, extend, and fit features without touching the underlying data infrastructure.
Feature Discovery → · Extensibility → · Data Preparation →
Component Neural Design#
A drag-and-drop canvas for assembling neural architectures from reusable components: CNNs, LSTMs, GRUs, Transformers, SlowFast networks. The AI can manipulate the same serialized JSON that the canvas uses — design visually or let the agent explore architectures programmatically.
Design Canvas → · Composable Architectures →
Training & Experiment Tracking#
Every training run is automatically tracked and comparable. Pause a run mid-epoch, adjust hyperparameters, and resume from the last checkpoint — preserving learned weights. Run hundreds of experiments systematically without losing track of what worked.
Experiment Tracking → · Model Vault → · Continuous Learning → · SmartFit →
Explainable AI#
Understand what your model is actually responding to. Saliency analysis shows which inputs drive predictions. Counterfactual tools answer "what would have to change for a different outcome?" Causal interpretation goes beyond correlation.
Counterfactual → · Causal Analysis →
Deployment#
Take trained models to production. Stream live data through deployed models, manage inference targets, and monitor performance.
Why Local Matters#
Everything runs on your machine. Sessions, models, training data, conversation history — stored in ~/.config/lit/, nothing sent to LIT.AI servers. When you're working with proprietary market data or sensitive research, that's not a detail.
On team deployments with Keycloak, tools execute as the authenticated user — inheriting your actual permissions from your existing identity system, with a complete audit trail.
Getting Started#
| Option | Who It's For | Commercial use |
|---|---|---|
| pip install | Personal and non-commercial use — full single-user platform, free permanently | License → |
| AWS Marketplace | Teams wanting cloud deployment with pre-configured GPU and Docker | ✓ |
| Self-hosted | Organizations deploying on existing infrastructure with multi-user support | ✓ |